2022. 4. 12. 13:21ㆍAlgorithm
학습목표
1. Huffman Coding에 대해서 학습
2. Prefix Code에 대해서 학습
3. Huffman Coding 수행과정에 대해서 학습
4. Run-Length Encoding에 대해서 학습
1. Huffman Coding이란 무엇인가?
- 허프만 코딩은 입력 파일의 문자 빈도수를 가지고 최소힙을 이용하여 파일을 압축하는 과정입니다.
- 예를 들어 6개의 문자 a, b, c, d, e, f로 이루어진 파일이 있다고 가정합니다. 문자의 총 개수는 100,000개이고 각 문자의 등장 횟수는 다음과 같습니다.

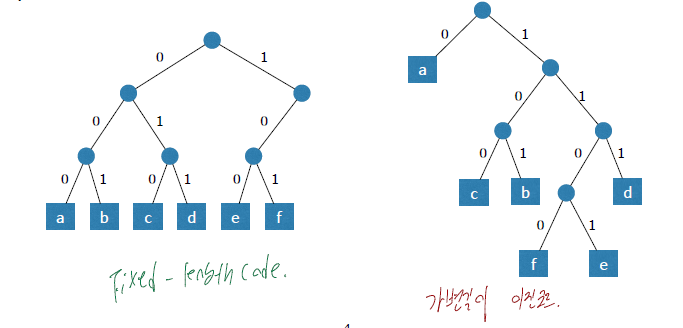
위 그림에 따른 Fixed-length code 방식의 필요 비트 수
- 각각의 문자를 표현하기 위해서 3비트가 필요하며, 파일의 길이는 300,000 bit가 됩니다.
위 그림에 따른 Variable-length code 방식의 필요 비트 수
- a=1bit, b=3bit, ..., f=4bit로 대응하여 비트 수를 세면 224,000 bit가 됩니다.
위 설명을 표로 표현하면 다음과 같습니다.

위 그림의 결론은 Fixed-length code 방식보다 Variable-length code 방식으로 파일의 압축을 수행하면 파일의 크기를 더 줄일 수 있다는 것을 알 수 있습니다.
Q. Variable-length code를 사용하여 파일의 크기를 300,000bit에서 224,000 bit로 줄일 수 있다면 문자 a, b, c, d, e, f에 대해서 a=0, b=1, c=00, d=01, e=10, f=11와 같이 표현하면 더 줄일 수 있지 않는가?
A. 물론 encoding 수행시 위와 같이 수행하면 파일의 크기를 더 줄일 수 있다. 하지만 압축을 수행하면 그 반대인 decode도 수행하여 압축했떤 문자를 복원할 수 있어야 한다. 위와 같이 2bit로 수행하면 decoding 수행시 압축했던 문자로 복원이 불가능하기 때문에 안하는 것이다.
예를 들어 a=0, b=1, c=00일때 0001 이진 문자가 존재할때 0001은 aaab, acb, cab와 같이 여러가지로 해석될 수 있다.
Fixed-length code 방식은 3bit씩 끊어서 decoding하면 되기 때문에 해석이 여러가지로 나뉠 일이 없다. 하지만 위와 같이 Variable-length code를 사용하면 특정한 규칙이 없이 decode를 수행하면 해석이 여러가지로 나뉠 수 있다. 이때 필요한 기술이 Prefix Code이다.
2. Prefix Code
- Prefix code란 어떤 codeword도 다른 codeword의 prefix가 되지 않는 코드를 의미합니다.
- codeword란 하나의 문자에 부여된 이진 코드를 말합니다.
- 어떤 codeword도 다른 codeword의 접두어(prefix)가 되지 않습니다.
- 예를 들어 위의 표에서는 a=0, b=101, c=100, d=111, e=1101, f=1100을 의미합니다.
- 예를 들어 a=0이면 b, c, d, e, f 문자의 codeword는 0으로 시작하지 않습니다.
- Fixed-length code 방식도 하나의 Prefix code입니다.
- Prefix code를 정의하면 모호함(해석이 여러가지로 나뉘는)이 없이 decode가 가능합니다.
- Prefix code는 하나의 이진트리로 표현이 가능합니다.
3. Humman Coding 이진트리 생성 수행과정
- 각 노드에는 문자에 대한 빈도수 비율의 데이터가 저장됨
- 각 노드들 중 비율이 가장 작은 둘을 선택
- 가장 작은 둘을 자식 노드로 하는 이진 트리 생성, 부모 노드의 값은 두 노드의 비율의 합으로 저장됨
- 2번~3번 과정을 루트 노드(1.0)가 생성될때까지 반복함





정리하며
- Humman Coding : 파일에 각 문자들이 등장하는 상대적인 빈도수의 비율을 이용하여 각 문자에 대한 Prefix Code를 생성하고 파일의 길이가 가장 짧아지게 만드는 Codeword를 구하는 것이 Huffman Coding 알고리즘입니다.
- Codeword : 하나의 문자에 부여된 이진코드로써 어떤 codeword도 다른 codeword의 Prefix가 되지 않는다.
- Prefix Code : 어떤 Codeword도 다른 Codeword의 Prefix가 되지 않은 코드들
4. Run-Length Encoding
- Huffman Coding은 각 문자의 빈도수 비율을 이용하여 Prefix Code를 생성하여 압축을 수행한다.
- Run은 동일한 문자가 하나 혹은 그 이상 연속해서 나오는 것을 의미함
- 예를 들어 문자열 s = "aaabba"는 다음과 같은 3개의 run으로 구성됨 : "aaa", "bb", "a"
- Run-Length Encoding에서는 각각의 run을 그 "run을 구성하는 문자와" "run의 길이"의 순서쌍 (n, ch)로 인코딩합니다. 여기서 ch가 문자이고 n은 길이입니다.
- 예를 들어 문자열 s = "aaabba"일때 "3a2b1a"와 같이 인코딩 됩니다.
- Run-Lnegth Encoding은 길이가 긴 run들이 많은 경우에 효과적입니다.
- 예를 들어 이미지 픽셀 압축이 있습니다. 이미지 픽셀같은 경우 동일한 값이 연속되는 경우가 있기 때문입니다.
References
[인프런] 영리한 프로그래밍을 위한 알고리즘 강좌
'Algorithm' 카테고리의 다른 글
| [알고리즘][압축] 압축(Compression) #3 Huffman Tree 생성 (0) | 2022.04.18 |
|---|---|
| [알고리즘][압축] 압축(Compression) #2 Huffman Method with Run-Length Encoding (0) | 2022.04.14 |
| [알고리즘][동적계획법] 동적계획법 #6 Knapsack Problem (0) | 2022.04.04 |
| [알고리즘][동적계획법] 동적계획법 #5 Longest Common Subsequence (0) | 2022.03.25 |
| [알고리즘][동적계획법] 동적계획법 #4 Matrix-Chain Multiplication (0) | 2022.03.24 |